
Table Of Links
2 DEPENDENTLY-TYPED OBJECT-ORIENTED PROGRAMMING
4 DESIGN CONSTRAINTS AND SOLUTIONS
FORMALIZATION
In this section, we present the syntax, typing rules and operational semantics of our system. We divide this presentation into three subsections: In Section 5.1, we introduce the core of our system. We extend this core calculus by data types and pattern matching definitions in Section 5.2, and by codata types and copattern matching definitions in Section 5.3. We do not formalize local pattern and copattern matches.
Instead, local pattern and copattern matches are lifted to the top level before applying de- or refunctionalization, similar to the approach taken by Binder et al. [2019]. Some care must be taken to ensure that we close over all required terms, as the types of terms which are part of the closure might close over additional terms. For example, closing over v: Vec n requires us to also close over n. The main challenge for local pattern and copattern matches revolves around judgmental equality, which we discussed in Section 4.1.
5.1 Core System
In Figure 9 we define the syntax of our core system together with small examples in the rightmost column.

Following standard convention, we formalize our system up to 𝛼-renaming of bound variables x, y, z. We distinguish between contexts Γ, Δ and telescopes Ξ, Ψ. Contexts track the types of free variables and must always be closed. Telescopes are dependent parameter lists whose types may contain free variables bound in a context. If a telescope is closed, we may implicitly use it as a context. A substitution 𝜌, 𝜎 is an argument list to a telescope.
A program Θ is a list of declarations 𝛿, which are empty for now. There are five different kinds of expressions 𝑒, 𝑠, 𝑡: Variables are denoted as described above. We denote the type universe as Type. Type constructors T𝜌 instantiate a (co)data type with a substitution 𝜌. Calling a producer C is written C𝜎; invoking a consumer d uses the syntax 𝑒.d𝜎. The producer syntax denotes constructor calls for data types and codefinition calls for codata types.
The consumer syntax denotes destructor invocations for codata and definition calls for data types. For formalizing the core system, we closely follow the presentation by Hofmann [1997]. The rules for contexts, telescopes, and substitutions are standard, and we omit them here for space reasons. We will use the judgment forms ⊢Θ Γ ctx and Γ ⊢Θ Ξ tel to specify valid contexts and telescopes, respectively.
The judgment form Γ ⊢Θ 𝜎 : Ξ states that 𝜎 is a valid substitution for the telescope Ξ under context Γ. We also assume the Type-in-Type axiom, which is well-known to be inconsistent [Girard 1972; Hurkens 1995]. In this work, we do not enforce termination or productivity in our system. As adding the Type-in-Type axiom merely yields another source of possible divergence [Tennant 1982], we do not gain anything from avoiding this paradox, e.g. by using a hierarchy of universes. We therefore follow Eisenberg [2016] and opt for a simpler presentation using the Type-in-Type axiom.
5.2 Data Types and Dependent Pattern Matching
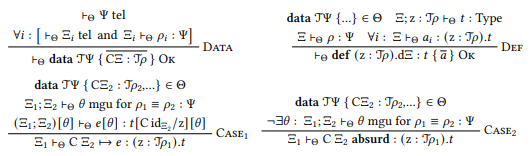
We now extend the declarations of Figure 9 by two new constructs: data type declarations and pattern matching definitions. Data type declarations introduce a new data type together with a list of constructors, and pattern matching definitions introduce a top-level consumer which is defined by a list of clauses. The corresponding new typing and well-formedness rules are contained in the upper half of Figure 10.

A data type declaration data TΨ { CΞ : T𝜌 } introduces one type constructor T and a list of term constructors C to the rest of the program. The type constructor T is indexed by a telescope Ψ, and if we provide a substitution 𝜌 for this telescope, then the formation rule F-Data allows us to form the type T𝜌. Each term constructor is declared with parameters Ξ and a type T𝜌 which specifies how the term constructor instantiates the indices of the type constructor.
We can use a term constructor with the introduction rule I-Data, where the resulting type depends on both the arguments 𝜎 to which the term constructor is applied and the substitution 𝜌 from the constructor declaration. We check that a data type declaration is well-formed with the help of the rule Data: For the type constructor T we check that the indices Ψ form a valid telescope in the program, and for each constructor CΞ : T𝜌 we check that Ξ is a valid telescope, and that 𝜌 is a valid substitution for the indices Ψ of the type constructor T under context Ξ. The second new construct is pattern matching definitions def (z : T𝜌).dΞ : 𝑡 { 𝑎 } which define a new consumer d by a list of cases.
The consumer d takes arguments specified by the telescope Ξ, and can be called on any term of type T𝜌, where the substitution 𝜌 can depend on any arguments bound in Ξ. The scrutinee of the consumer can be referred to by the self parameter z in the return type 𝑡 of d. We introduced these self-parameters in Section 2.1. The elimination rule E-Data then eliminates a term 𝑒 by invoking d with arguments 𝜎. These arguments are substituted in the return type 𝑡 which is defined under the context Ξ; 𝑧 : T𝜌. Here, the self parameter 𝑧 is replaced by the scrutinee 𝑒. We check whether a pattern matching definition is well-formed with the rule Def.
The return type 𝑡 is typed under context Ξ; z : T𝜌. We implicitly require that there exists exactly one case of each constructor C of T, and check that every case is well-formed. For checking the wellformedness of cases we use an auxiliary judgment form Ξ ⊢Θ 𝑎𝑖 : (𝑧 : T𝜌).𝑡 which tracks the self parameter z : T𝜌 and the return type 𝑡. There are two variants of pattern matching cases we have to consider: possible and absurd cases. In a possible case, we restate the constructor telescope Ξ and give an expression 𝑒 that gives the result if the case is matched. An absurd case is determined to be impossible by unification and hence does not need an expression.
Corresponding to the two kinds of cases, possible and absurd, there are two typing rules, Case1 and Case2. In both rules, we unify the scrutinee type T𝜌1 with the constructor type T𝜌2. If there is no such unifier, the case is absurd. In a possible case, however, unification yields a unifier 𝜃. We use this unifier to refine the typing of the right-hand side 𝑒: The unifier 𝜃 is substituted in the context Ξ1; Ξ2, expression 𝑒 and type 𝑡. We further refine 𝑡 by replacing the self parameter z with the constructor CidΞ2 where idΞ2 is the identity context morphism for Ξ2. Finally, the computation rule ≡-Data allows us to reduce an expression C𝜎1.d𝜎2 if 𝜎1 and 𝜎2 are valid arguments to the constructor respectively definition.
5.3 Codata Types and Dependent Copattern Matching
Finally, we extend programs by codata type declarations and copattern matching definitions. Codata type declarations introduce a new codata type together with a list of destructors, and copattern matching definitions introduce a new top-level producer by a list of copattern matching
**Declaration Rules**
**Formation, Introduction, Elimination and Computation Rules**

**Declaration Rules**

**Formation, Introduction, Elimination and Computation Rules**

clauses. Their typing and well-formedness rules are contained in the lower half of Figure 10.
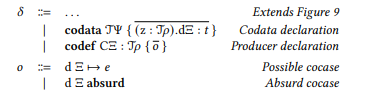
A codata type declaration codata TΨ { (z : T𝜌).dΞ : 𝑡 } introduces the type constructor T and a list of destructors d to the program. Like data types, codata types are indexed, and the type constructor T can be instantiated to form types with the help of the rule F-Codata. The signature of each destructor declaration (𝑧 : T𝜌).dΞ : 𝑡 corresponds precisely to the signature of a pattern matching definition for data types: Destructors take a parameter telescope Ξ and a self parameter (𝑧 : T𝜌), where 𝜌 is a substitution for the type parameters Ψ under context Ξ. The return type 𝑡 is defined under the context Ξ; 𝑧 : T𝜌.
Using the rule E-Codata, we can eliminate a term 𝑒 by calling a destructor d with arguments 𝜎. In order to obtain the type of 𝑒.d𝜎, we substitute 𝜎 for the parameters Ξ in the return type 𝑡, and 𝑒 for the self parameter z. We use the rule Codata to check that a codata type declaration is well-formed. A codefinition codef CΞ : T𝜌 { 𝑜 } has a signature which reflects the signature of constructors of a data type. The body of a codefinition is a list of cocases, which can be either possible or absurd.
In a possible cocase, we restate the telescope Ξ and give an expression 𝑒 which provides the result if the cocase gets matched. An absurd cocase is determined to be impossible by unification and hence does not need to provide an expression. We check whether codefinitions are well-formed with the help of the rule Codef: We check that the parameters Ξ are valid and that the arguments 𝜌 to the type constructor are well-typed under context Ξ. Further, we ensure that all cocases 𝑜𝑖 are well-formed with the auxiliary judgment form Ξ ⊢Θ 𝑚𝑑 𝑖 : (𝐶 : T 𝜌), which tracks label C and type T 𝜌 of the codefinition.
We implicitly require that there exists one cocase for each destructor d of T. As with pattern matching cases for data types, there are possible and absurd cocases as specified by the rules Cocase1 and Cocase2. Which rule applies is determined by unifying the codefinition type T𝜌1 with the destructor type T𝜌2. If no such unifier exists, the cocase is absurd. In a possible cocase, the unifier 𝜃 is substituted in context Ξ1; Ξ2, expression 𝑒, and type 𝑡. We also refine the return type 𝑡 by substituting C idΞ1 , where idΞ1 is the identity context morphism for Ξ1.
Reminiscent of constructor calls, I-Codata introduces a term of such a type by invoking a codefinition C with arguments 𝜎 for the parameters Ξ. As these parameters Ξ may occur in the constructed type T 𝜌, we substitute the arguments 𝜎 in the type. Lastly, the computation rule ≡-Codata reduces a redex C𝜎1.d𝜎2 if 𝜎1 is a valid argument for the codefinition C and 𝜎2 is a valid argument for the destructor d.
5.4 Call-By-Value Operational Semantics
The computation rules of Section 5.2 and Section 5.3 do not specify a deterministic evaluation order. In this section we present the call-by-value (CBV) operational semantics of our system; the operational semantics does not depend on typing information. We specify evaluation by means of evaluation contexts in the style of Felleisen and Hieb [1992]. Values consist of the type universe or of type constructors and named producers applied to other values. Named producers can either be the constructors of a data type or the call to a toplevel l codefinition. Such codefinitions generalize lambda abstractions which are lifted to the toplevel.
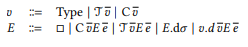
Reduction 𝑒 ⊲ 𝑒 ′ happens when introduction and elimination forms meet, i.e. when a method is called on a constructor, or when a destructor is invoked on a codefinition:
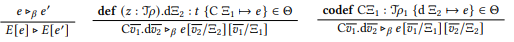
Here, ⊲𝛽 denotes single step reduction of a direct redex, while ⊲ denotes evaluation within an evaluation context.
5.5 Type Soundness
We show type soundness with respect to the call-by-value semantics of Section 5.4 by the usual progress and preservation theorems. TheoRem 5.1 (PRogRess). For any well-formed program Θ and expressions 𝑒 and 𝑡, if ⊢Θ 𝑒 : 𝑡 then either 𝑒 is a value or there exists an expression 𝑒 ′ such that 𝑒 ⊲ 𝑒 ′ . PRoof. See Appendix A.1. □ TheoRem 5.2 (PReseRvation). For any well-formed program Θ and any expressions 𝑒1, 𝑒2, 𝑡 if ⊢Θ 𝑒1 : 𝑡 and 𝑒1 ⊲ 𝑒2, then ⊢Θ 𝑒2 : 𝑡.
This paper is