

This paper is available on arxiv under CC 4.0 license.
Authors:
(1) Zhouqiang Jiang, Meetyou AI Lab,
(2) Bowen Wang, Institute for Datability Science, Osaka University,
(3) Tong Xiang, Meetyou AI Lab,
(4) Zhaofeng Niu, Department of Computer Science, Qufu Normal University,
(5) Hong Tang, Department of Information Engineering, East China Jiaotong University,
(6) Guangshun Li, Department of Computer Science, Qufu Normal University,
(7) Liangzhi Li, Meetyou AI Lab.
Table of Links
IV. EXPERIMENTS
A. Pre-training
Architecture. By default, we use ViT-S/16 as the encoder, with a depth of 12 and a width of 384, which is similar to ResNet-50 [46] in terms of the number of parameters (21M vs. 23M). We use a small decoder with a width of 256 and a depth of 4. The effectiveness of this setup is demonstrated in Table IIIb and IIIc.
Settings. We conduct self-supervised pre-training on the Kinetics-400 [7] action recognition dataset, which encompasses a total of 400 classes, comprising 240k training videos and 20k validation videos, and we only conduct pretraining on the training set. Considering the cost of training, we default to sampling three frames (224x224) from each video at certain frame intervals, and employ two image augmentation methods: RandomResizeCrop and horizontal flipping. A large portion (95%) of the patches in the last two frames are randomly masked, and the batch size is 2048. The base learning rate is initialized to 1e-4 and follows a cosine schedule decay. We use the AdamW [47] optimizer, and the reconstruction losses for the second and 3rd frames are scaled by 0.8 and 1.0, respectively. We adopt a repetition sampling [4], [48] factor of 2 and finally conduct pre-training for 800 effective epochs.
B. Evaluation Method
We conduct two downstream experiments, video segmentation and action recognition, to evaluate the correspondence and motion information of the obtained representations.
Fine-grained Correspondence Task. We use the semi supervised video segmentation dataset DAVIS-2017 [9] to evaluate the quality of representations in fine-grained correspondence tasks. We adopt the label propagation method used in [49], [4] to implement semi-supervised video segmentation. Given the ground truth labels of the first frame, we obtain k-nearest neighbor results through a similarity function between frames. Afterward, the ground truth labels of the first frame are propagated to subsequent frames as pixel labels, based on the k-nearest neighbors’ results.
Action Recognition Task. We followed the evaluation protocol of VideoMAE [2] for the motion evaluation on action recognition task by Kinetics-400 [7]. In order to avoid a variety of meticulously crafted fine-tuning settings obstructing fair comparisons between different pre-training methods, we used the same pipeline to uniformly fine-tune all pre-trained models on the training set for 150 epochs and report the results on the validation set. To fairly compare with video MAEs [2], [3], we also will extend the 2D patch embedding layer to a 3D embedding layer following the approach proposed in [7].
C. Main Results and Analysis
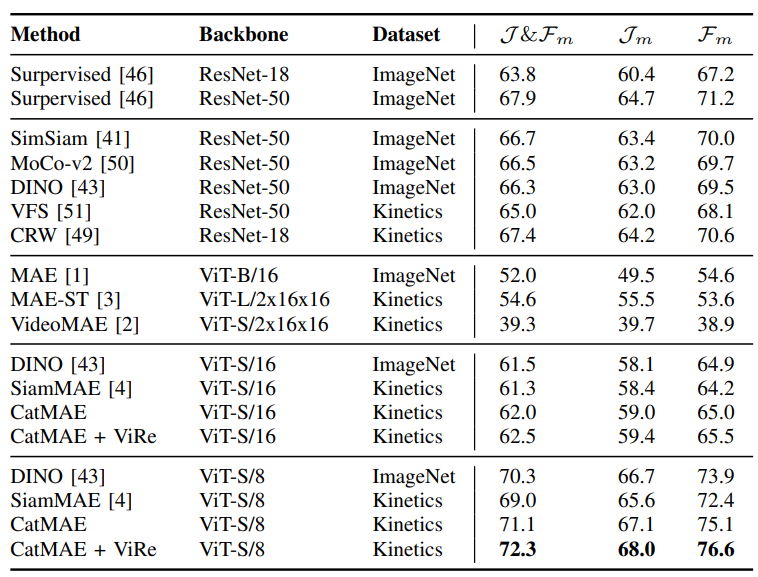
Fine-grained Correspondence Task. Table I demonstrates all the methods using 480x880 images. We find that CatMAE-ViT-S/8 surpasses all other self-supervised or supervised methods, and its performance is further enhanced when ViRe is applied. This demonstrates that using reversed videos as reconstruction targets can further enhance the model’s ability to match correspondences. As analyzed before, the cube masking recovery strategy cannot learn the inter-frame correspondence, resulting in MAE-ST and VideoMAE being significantly lower than CatMAE. In addition, CatMAE also outperforms SiamMAE by a large margin, owning a better segmentation performance with larger frame intervals (Table IIIa), proving that using the concatenated information channel masking strategy can capture longer and more accurate correspondences in videos.
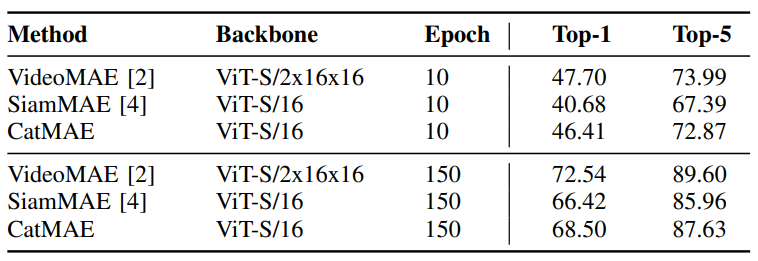
Action Recognition Task. We implement this experiment with two competitive video representation methods VideoMAE and SiamMAE. All methods undergo 800 epochs pretraining. In Table II, it is observed that during the early stage of fine-tuning, CatMAE exhibits a significantly stronger transfer capability than SiamMAE, with an enhancement in top-1 accuracy by 5.73%. This indicates that our proposed concatenated information channel masking reconstruction pre-training strategy can capture more motion information than the asymmetric mask reconstruction strategy of SiamMAE. Even when the fine-tuning saturates, CatMAE still leads SiamMAE by 2.08% in top-1 accuracy. However, the gap between CatMAE and VideoMAE widen, which we believe mainly stems from the method of modeling tokens. VideoMAE directly models token embedding using a 3D cube, which essentially makes VideoMAE a type of 3D network. VideoMAE naturally contains more motion information than CatMAE which encodes 2D patch as tokens. Yet, in the initial stage of fine-tuning, CatMAE manages to maintain comparable transfer ability to VideoMAE (only 1.29% lower in top-1 accuracy), performing far better than the SiamMAE (7.02% lower). Our CatMAE maximally exploits the motion information on the 2D patch.
D. Ablation Experiments
We conduct an ablation experiment to understand each component’s contribution. Details can be found in Table III. Number of Reconstructions. Fig. 1 shows the model’s reconstruction results for future frames. As can be seen, the model is highly sensitive to motion elements in video frames. In Fig. 1a, the model can distinguish between static backgrounds and accurately reconstruct the motion of waving hammers. Beyond its motion modeling capability, the model can copy the background from the first frame and paste it into future frames when dealing with static backgrounds (such as the static woodpile). As shown in Table IIIa, the video segmentation performance steadily improves with the increase in the number of reconstructions. When the number of reconstructions is 4, the performance is higher in comparison with the number being 1 (↑3.9%). This validates the benefits of using a concatenated information channel masking strategy to extend multi-frame reconstruction.
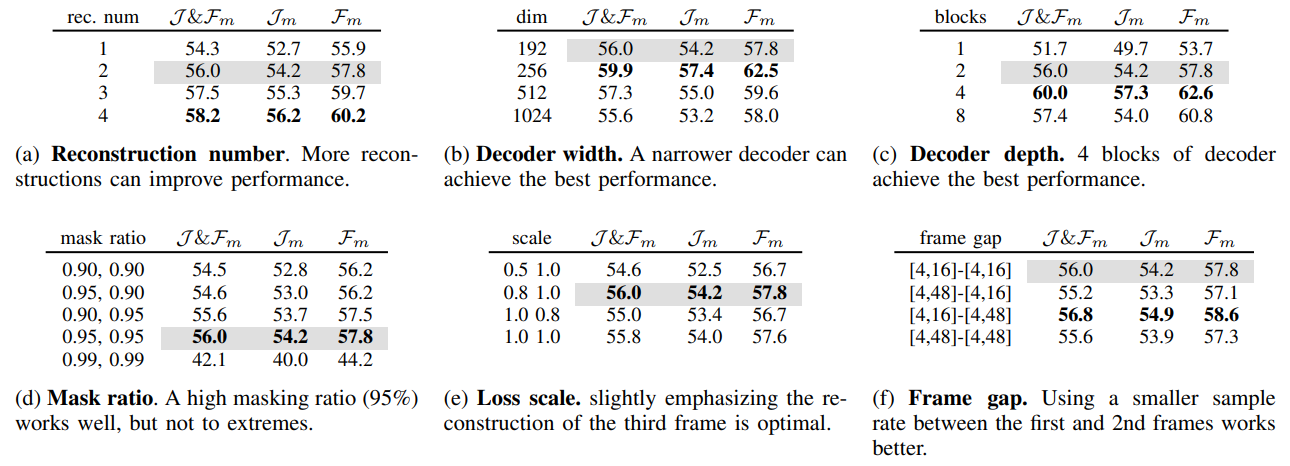
Decoder Capacity. In Table IIIb and IIIc, we respectively examine the width and depth of the decoder. We found that relative to the encoder (384-d, 12-block), a smaller decoder (192-d, 4-block) is critically important for fine-grained correspondence tasks. This can be explained by the relationship between pixel reconstruction and fine-grained feature correspondence: during pixel reconstruction, the encoder is sensitive to motion offsets, thus obtaining a more reasonable correspondence representation. However, when the decoder capacity is too large, it weakens the encoder’s sensitivity to motion. Therefore, in terms of the width and depth settings for the decoder, an optimal width of 256 is 4.3% better than the maximum width of 1024 (59.9% vs. 55.6%). Additionally, an optimal depth of 4 is 2.6% better than the depth of 8 (60.0% vs. 57.4%). These optimal decoder capacities are much smaller than the encoder, underscoring the importance of utilizing a smaller decoder.
Mask Ratio. In Table IIId, we compare different mask ratio. Based on previous experience with video MAEs, we default to ablating from a high mask ratio (90%), but under such a high mask ratio, increasing the mask ratio of the last two frames to 95% still shows performance improvement (54.5% vs. 56.0%). However, when using an extreme mask ratio of 99% (Only one patch is visible), the performance drops sharply. An information channel with limited capacity is crucial for the model to learn correspondences. However, when the channel capacity is reduced to its extreme limit, it becomes difficult for the model to match correspondences. Hence, we default to using a mask ratio of 95%.
Loss Scale. In Table IIIe, we compared the reconstruction loss scale between the second and third frames. We found that slightly emphasizing the reconstruction of the third frame is better than that of the second (compare the second and third rows in Table IIIe). We believe that focusing more on the third frame’s reconstruction facilitates the progressive transmission of continuous motion information to the final frame. However, neglecting the reconstruction of the second frame by reducing its loss scale to 0.5 leads to performance degradation. This might weaken the model’s capability to capture the intermediate motion, thus affecting the propagation of continuous motion information.
![Fig. 4: Cross-attention maps from a ViT-S/16 decoder (samples from DAVIS-2017 [9]). We visualize the attention of themask patch to be reconstructed in the third frame towards the visible patches in the first and second frames at the average](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-wbc3vga.png)
Frame Gap. In Table IIIf, we compare different frame gaps. While a larger frame gap sampling can encompass richer motion information, reconstructing two frames with large gaps does not bring performance improvement to the model (compare the first and fourth rows). This may be because when the frame gap becomes too large, the scene changes are too dramatic, which hinders the model’s ability to model motion information. Additionally, we found that having a smaller gap between the first and second frames and a larger gap between the second and third frames (see the third row in Table) performs better than the reverse configuration (see the second row in Table) (56.8% vs. 55.2%). This observation can also be interpreted as the propagation of continuous motion being hindered: a large gap between the first and second frames makes capturing intermediate motion difficult, thereby blocking the transmission of continuous motion information within the information channels.
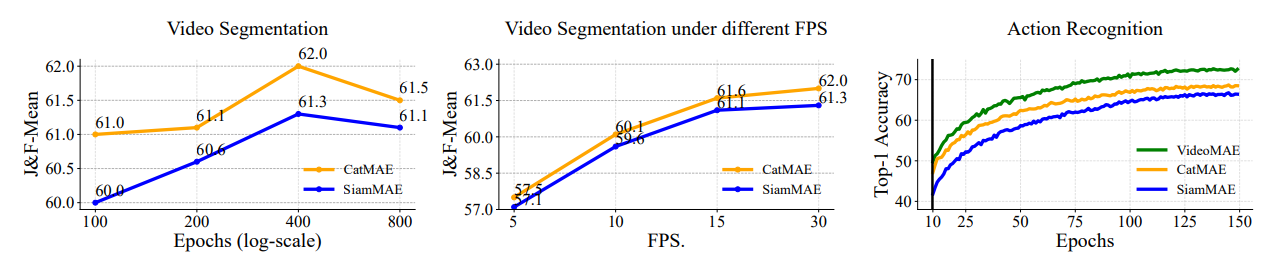
Training Epochs and Propagation FPS. In Fig. 3, we analyze the impact of training epochs and propagation FPS on video segmentation, discovering that optimal performance is achieved at pre-training 400 epochs, after which the performance gradually declines, possibly due to overfitting caused by small decoder. We observe that under various low FPS conditions, CatMAE consistently outperforms SiamMAE, demonstrating that CatMAE possesses a stronger ability to match long-term correspondences. Additionally, we delve into the influence of fine-tuning epochs. CatMAE initially exhibits robust transferability but the gap widens with VideoMAE over time due to differences in token embedding. Simplistically speaking, CatMAE can be seen as a ”additional frame reconstruction” version of SiamMAE. Therefore, according to Action Recognition figure, we estimate that using CatMAE to pre-train weights for reconstructing future four frames holds promise for reaching the fine-tuning performance of VideoMAE.
E. Motion and Correspondence Analysis
In Fig. 4, we visualize the cross-attention map averaged across different heads in the final layer of the ViT-S/16 decoder. Specifically, we input the first frame and the subsequent two frames with masks, followed by reconstructing the third frame. We collect the cross-attention from the mask patch in the third frame towards the visible patches in the first and second frames and then visualize this attention map. We find that the model is sensitive to motion, focusing on the correspondence between patches under continuous motion. For instance (Fig. 4a), when calculating the correspondence of the horse’s head patch in the third frame, the model can clearly distinguish the semantics of the brown region and attention accurately focused on the head of the horse in previous frames.
Even when the background color is similar to the possible corresponding area (such as the white head of the water bird and the reflective water surface Fig. 4b), the model’s corresponding capability remains robust. Certainly, the model can also establish correspondences by leveraging unique color features (such as the red bill of a swan Fig. 4c) or specific semantic structures (such as the fin of an Orca Fig. 4d). These provide direct evidence of the model’s ability to estimate motion and learn correspondences.